Working with Remote Data Sources
TQ Data Foundation stores all asset collections in its own internal database, which is based on the open-source Jena TDB project. This database is optimized for query speed as it sits close to the query algorithms that drive Data Foundation. However, there are scenarios where it is desirable to use external “remote” data bases such as triple stores from commercial vendors.
External triple stores may offer better scalability, i.e. going into billions of triples
Some data may be controlled or also used by other applications than Data Foundation
These use cases often involve external knowledge graphs that are edited outside of Data Foundation, such as Wikidata, SNOMED, UniProt or other biomedical databases.
Data Foundation offers support for so-called Remote Data Sources. Initial support includes arbitrary data sources that offer an endpoint following the standard SPARQL 1.1 HTTP protocol. Using this feature, Data Foundation can seamlessly interact with data stored on external SPARQL databases and treat them as “virtual” asset collections.
Example: Geo Taxonomy uses Wikidata
When you have installed the latest version of the Geography Taxonomy from the TQ Data Foundation samples, you can see that the Geo Taxonomy has a link from its Iceland asset to a corresponding Iceland entity on Wikidata using the property wikidata country:
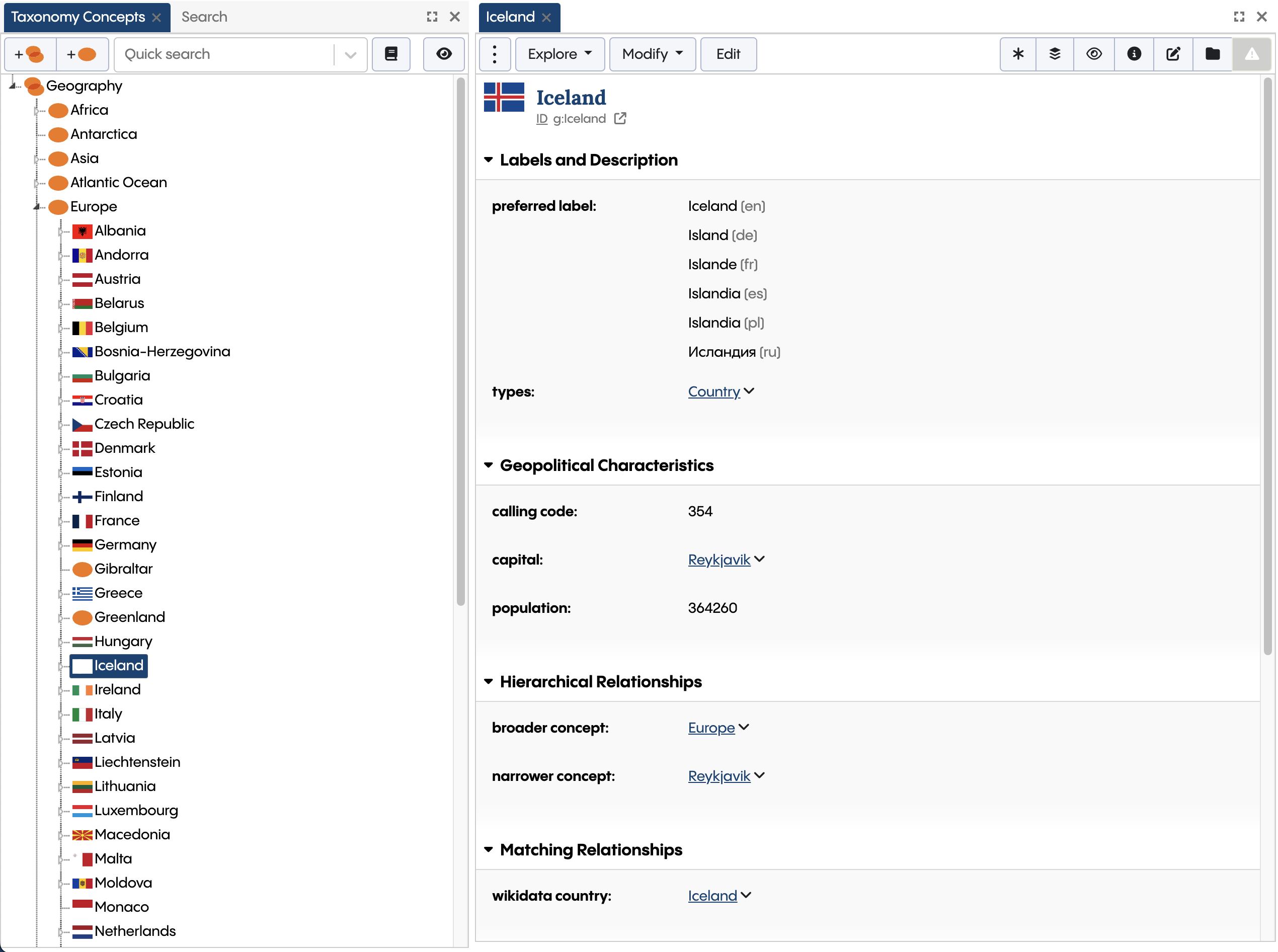
The country Iceland from the Geo Taxonomy points at the corresponding Iceland entity on Wikidata
Now, you click on that link, the system will show the form for the remote asset which is, in fact, stored remotely on the public Wikidata endpoint:
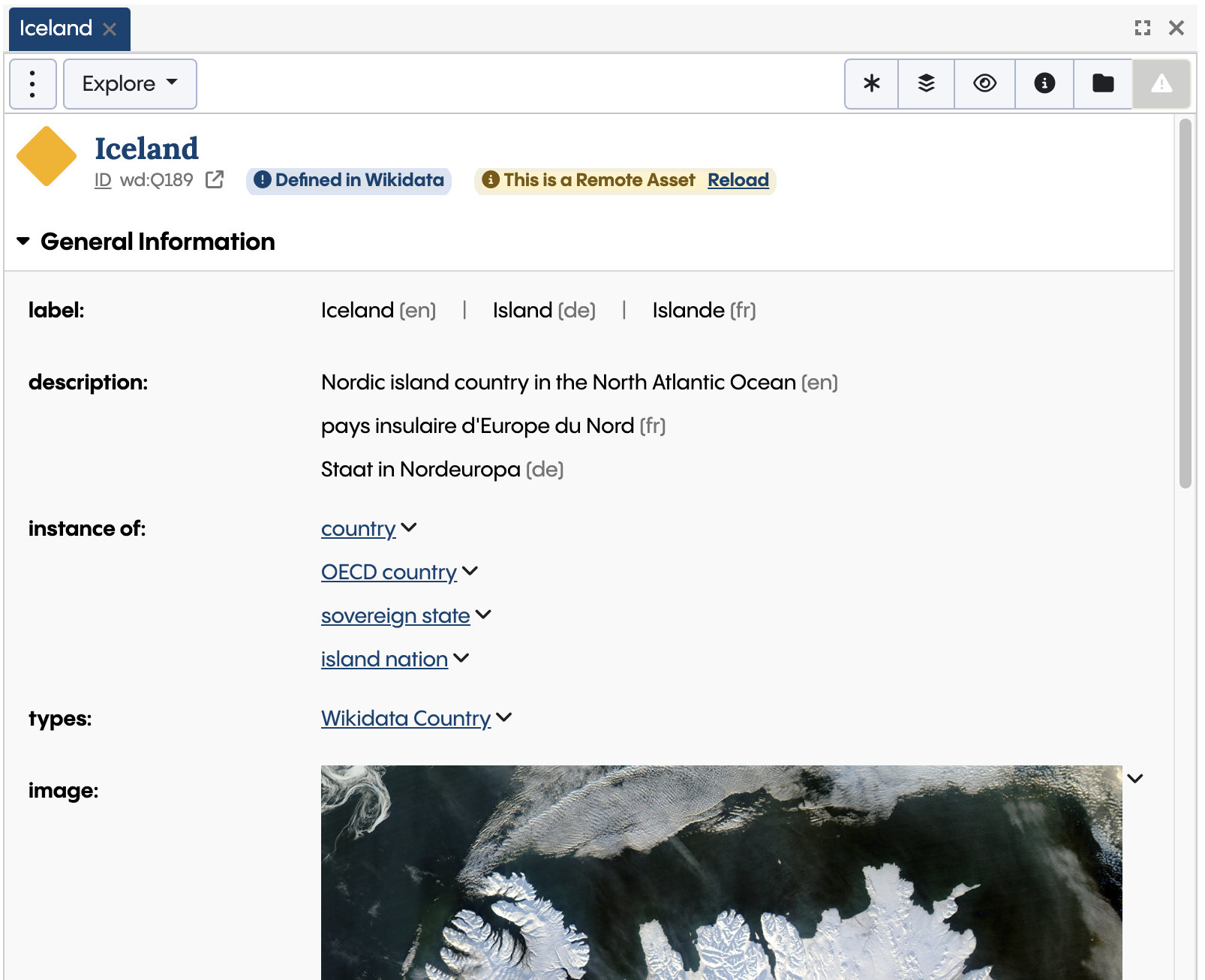
The properties of the Wikidata country Iceland
Attention
Assets that are stored on remote data sources such as Wikidata will be loaded into Data Foundation’s internal database when needed and then act like any other locally stored asset.
Example: Searching Remote Assets
When you navigate to the Wikidata Data Graph from the TQ Data Foundation samples, you can search across various classes such as Wikidata Country using the search panel. Data Foundation understands that in order to retrieve matching countries, it needs to issue a SPARQL query against the remote endpoint.
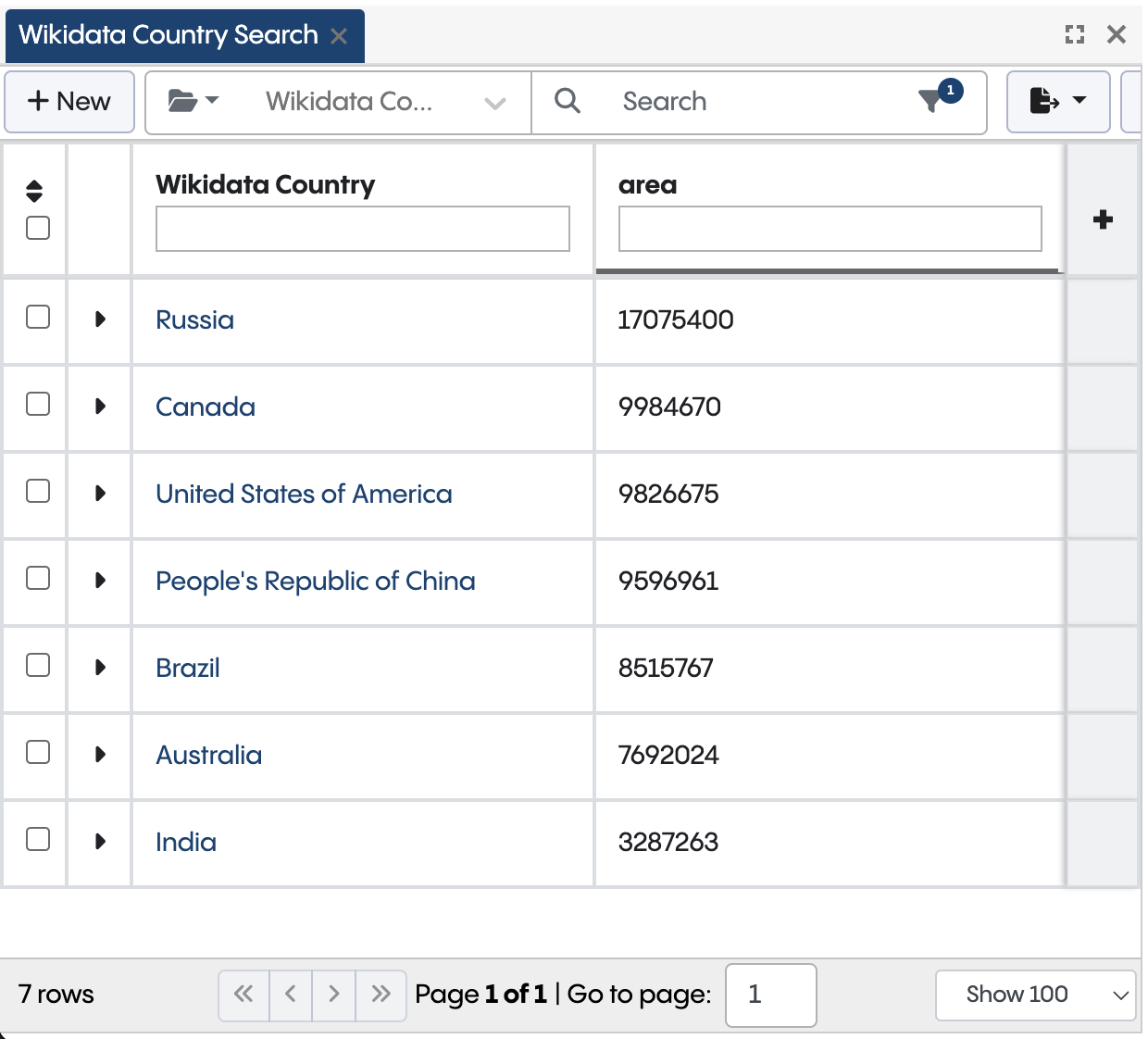
When configured for remote assets, the Search form queries the SPARQL endpoint directly
This capability means that you can now access data sources that are traditionally too large to handle efficiently from Data Foundation.
Architecture of Remote Data Sources
Before we go into the set up processes for remote data sources, it is helpful to understand a bit about Data Foundation’s graph architecture. The figure below illustrates the graphs involved in such a scenario. In this example the asset collection “Geo Taxonomy” has been opened by the user. The Geo Taxonomy includes (owl:imports) a Data Graph called “Wikidata” which in turn includes an Ontology called “Wikidata Ontology”.
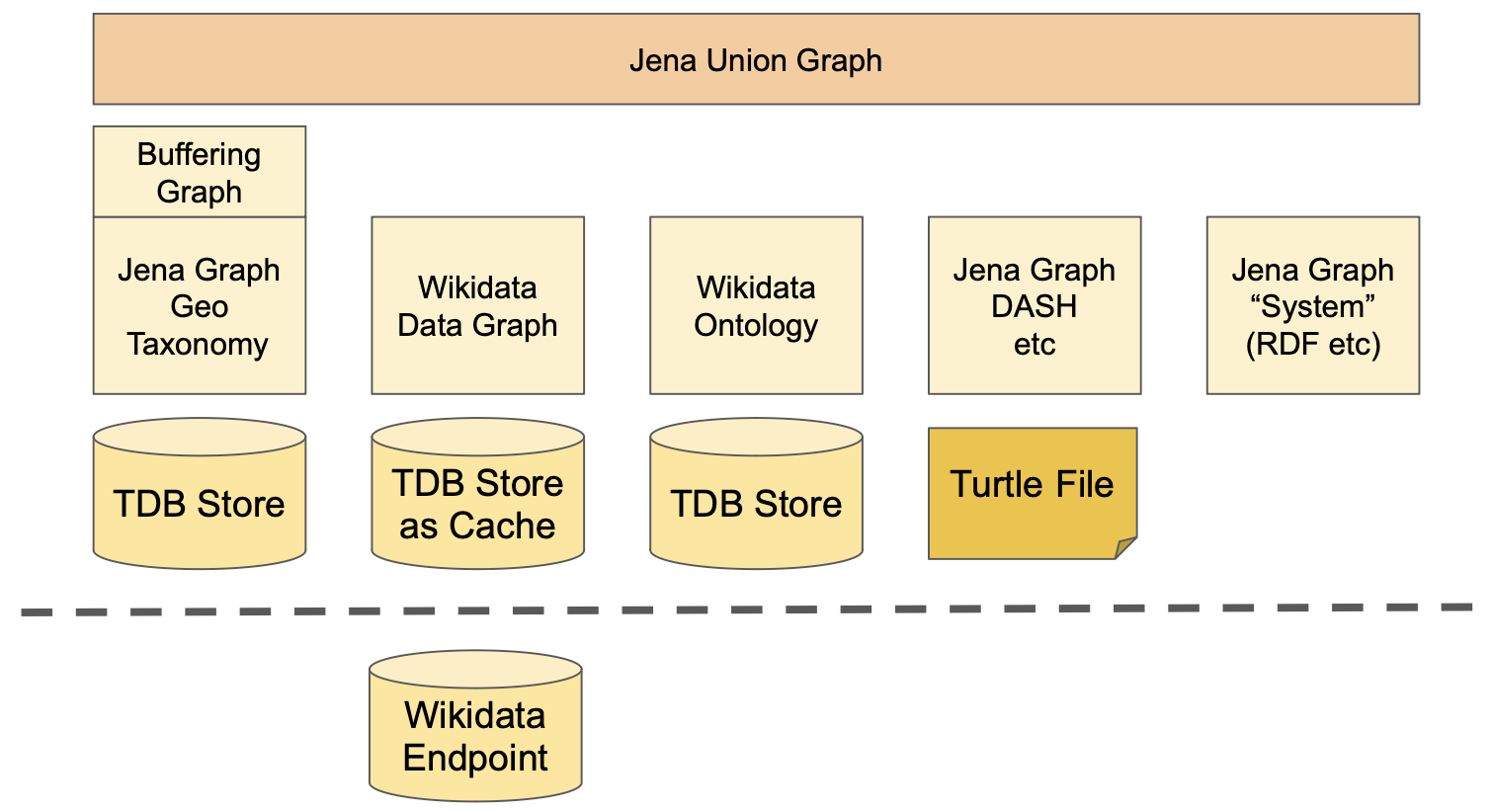
Architecture with Wikidata as a Remote Data Source
The Wikidata Data Graph uses the Wikidata SPARQL endpoint to provide a virtual view on basically any data stored in Wikidata. While all asset collections use the local TDB database, the Wikidata asset collection uses its TDB only as a “cache” of sorts, which is only populated with the subset of Wikidata that is actually relevant. For example, once a user visits a Wikidata asset, Data Foundation will
Fetch the label and type(s) of that asset
Based on the type information, load all properties that are defined for the classes
Whenever an asset is loaded, Data Foundation remembers the time stamp alongside the other RDF triples. Data Foundation uses that time stamp to determine whether an asset is already loaded or not.
Note
Data Foundation’s remote asset support means that you can connect your own assets to data stored in external databases without having to copy the whole external database into Data Foundation’s local database. Data Foundation will only ever “see” the parts that are relevant to the local use case.
The following figure illustrates how this works:
Data Foundation's remote storage mechanism uses SHACL shapes to determine which subset of values to load into the cache
The class and shape definitions are already used by Data Foundation’s Form, Search and Asset Hierarchy panels, where they act like filters or views on the underlying data. The remote data support relies on exactly the same classes and shapes. So for example, when you browse to a country in Wikidata, it would only download exactly the properties defined for the Country class in the associated ontology, while the bulk of other properties remain on the remote server only. Likewise you can only query instances of classes that are known to be present on the remote server.
Complete Mode
By default, Data Foundation will dynamically load assets from the remote SPARQL endpoint, when they are needed. However, starting with version 8.0, asset collections may also operate in complete mode, in which all data is assumed to be present both in the local database and the remote endpoint. The benefit is that no dynamic loading of triples is needed, yielding much better performance. Basically such asset collections operate as normal, with the full set of features, only that the changes to the production copies will also be written to the remote database.
Warning
Complete mode is only suitable for asset collections that fit into the usual size constraints of the database, i.e. typically up to tens of millions of triples but not necessarily more. Complete mode also assumes that all edits to the remote database happen through Data Foundation.
Note
Complete mode is automatically activated when the asset collection is an Ontology. This is because Ontologies contain class and property definitions that drives the behaviour of the system, and this information must be available at all time.
Configuring Remote Asset collections
Depending on your starting point, there are various ways to get started with remote asset collections.
In all cases, Data Foundation assumes that the remote SPARQL endpoint already exists. For example, for GraphDB you should set up a GraphDB repository using the GraphDB software, then use its link button to copy the URL of its SPARQL endpoint.
The Globally Configured Endpoint
A system administrator or power users can enter the connection details for a remote SPARQL endpoint on the product configuration administration page. They need to enter the endpoint’s URL and possibly user name and password. If the setting use endpoint for new collections is activated, any newly created asset collection will then automatically be linked to the specified endpoint. Each asset collection will become a named graph under that endpoint.
The remote endpoint is assumed to operate in complete mode, i.e. the triples on the local database and the remote triples will always be kept in sync, so that edits made through Data Foundation will be written to the database as well.
Hint
This is the easiest way to use Data Foundation’s remote data support, but makes the assumption that all asset collections will be written to the same place. It can however also be combined with manually configured asset collections that may, for example, be read-only remote endpoints that are stored elsewhere. It is also possible to deactivate the complete mode setting at a later stage, when an asset collection becomes too large to be handled within Data Foundation’s own database or you plan to make changes to your endpoint from outside of Data Foundation.
Import Remote Asset Collection
When you already have data on a SPARQL endpoint, you can create a new asset collection for it using the global New Button and then Import Remote Asset Collection. This will open a wizard where you can fill in the following details:
asset collection name: The display name of the new data graph or taxonomy that mirrors the remote data.
SPARQL endpoint URL: The URL of the SPARQL endpoint holding the data.
endpoint implementation: Here you should select the most appropriate type, e.g. GraphDB.
remote named graph: Use this if your data is not stored in the default graph of the SPARQL endpoint.
complete mode: Set this to true to activate Complete Mode.
collection type: The type of asset collection to create. This defaults to Data Graph, then Taxonomy, then Ontology depending on available license.
editable: Set this to true if the remote database can be modified.
generate Ontology: Set to true if you also want to have an Ontology generated in addition to the data graph/taxonomy. Leave this at false if you already have an ontology describing the classes and properties of your data. You can also run the same ontology generation algorithm later, from any ontology, using Modify > SHACL Ontology from SPARQL Endpoint… at an Ontology’s Home asset. The algorithm behind that will issue a sequence of SPARQL queries to indentify used classes and properties, including some logic to find suitable SHACL constraints on them. Note however that this Ontology should only be seen as a starting point and you will likely want to perform manual clean-ups later, esp to rearrange classes into subclass relationships. For expert users, the algorithm can be found in the file teamwork.topbraidlive.org/api/toshremote.api.ttl - please let us know if you have suggestions on how to improve it.
Export to Remote Graph
When you already have an asset collection in Data Foundation and want to mirror it into a remote SPARQL endpoint, go to the Home asset and find Modify > Export to remote graph…. This opens a dialog where you can select the following:
SPARQL endpoint URL: The URL of the SPARQL endpoint that shall be holding the data. This is assumed to be empty.
endpoint implementation: Here you should select the most appropriate type, e.g. GraphDB.
remote named graph: Use this if your data shall not be stored in the default graph of the SPARQL endpoint.
complete mode: True to activate complete mode. This is recommended unless you expect your data to grow beyond what Data Foundation can typically handle in its own database, or when you expect external processes to also update the remote database directly.
When you Ok this dialog, it will configure your asset collection with the necessary metadata and then copy all its content onto the remote endpoint.
Manual Configuration
If the above processes are not working for you, or if you want to modify an existing asset collection, here is the manual process. If you are new to this, please also read the remainder of this section for technical background of how it all works.
Create an initially empty asset collection for the remote data. In many cases you will find that Data Graphs are the most flexible way of working with remote data, but if your remote data is in SKOS, you may also select a Taxonomy.
With the newly created asset collection, use the Settings > Includes section to include the graph called Data Foundation Remote Data Support. When you back to the “Home” asset of your asset collection, you should then see a new form section *
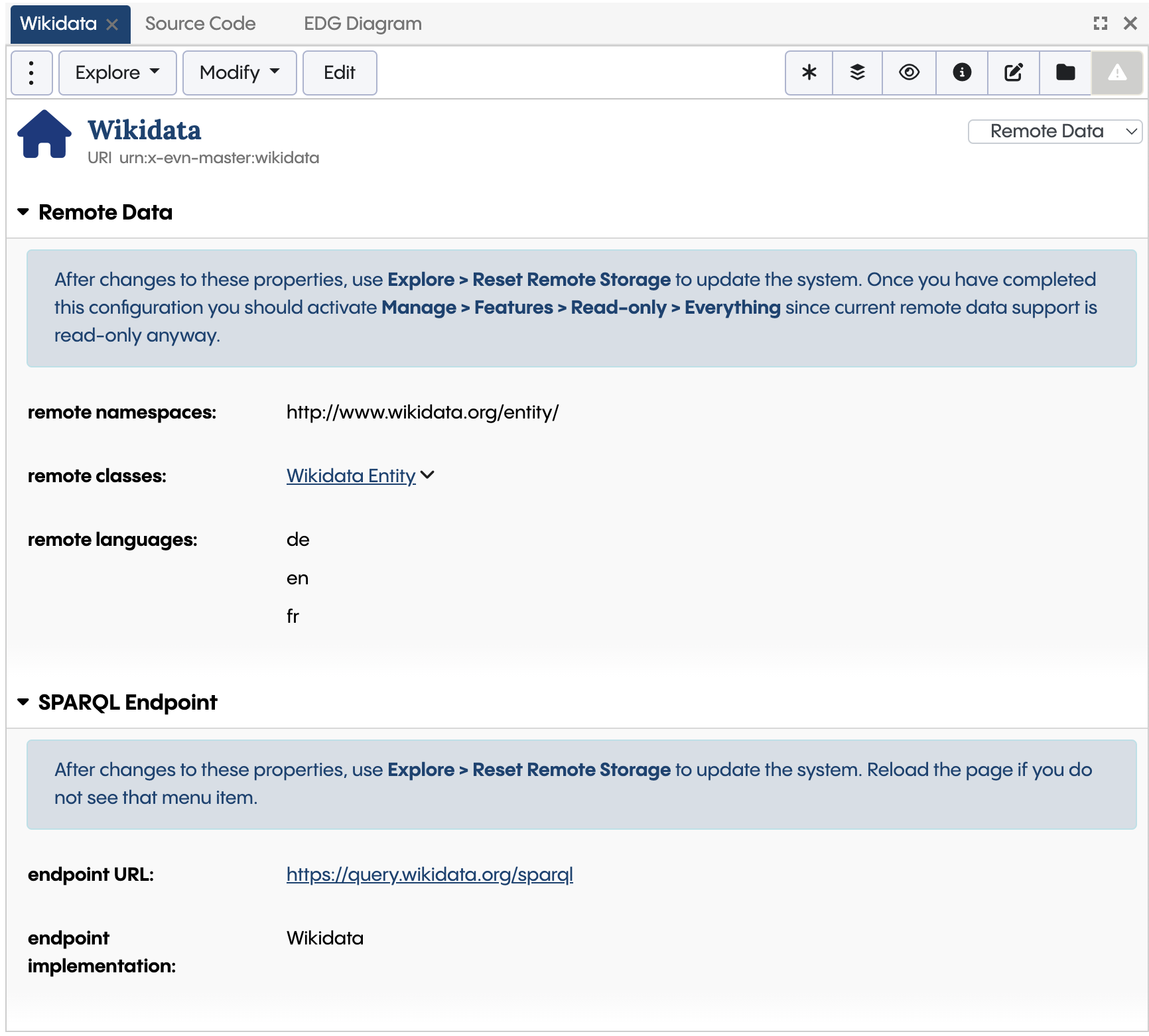
Use the Remote Data view of the Home asset (here: for the Wikidata Data Graph) to configure access to a remote data source
On that form, start with entering the URL of the SPARQL endpoint. Under endpoint implementation check if your database is listed among the available options. For example, Data Foundation has optimizations for GraphDB and Stardog to make use of the faster text search indices of these databases. Also verify if any of the other properties of the SPARQL Endpoint section apply to your database.
Use the property remote is editable if you want users to be able to modify the data on the SPARQL endpoint. By default this is off, meaning that users can only browse.
Then save the changes and reload the page in the browser. You should then use Explore > Reset Remote Storage… to inform Data Foundation that your asset collection shall be treated as a container for remote data. Unless remote is editable is true, this essentially makes the asset collection read-only and disallows any edits except to the Home asset. Instead, Data Foundation will manage the updates to this asset collection, for example by loading missing assets when they are needed.
Attention
You need to use Explore > Reset Remote Storage after any change that may affect access to your remote data. This includes changes to the Remote Data section on the Home asset, but also any changes to the Ontologies that describe which classes and instances are present on the remote data source.
With the connection to the SPARQL endpoint just established, the asset collection will be empty by default. Unless the asset collection operates in complete mode, you need to use the following properties to instruct Data Foundation about which assets and instances of which classes exist on the remote data source:
Remote namespaces must enumerate the namespaces of all assets on the remote data source that you want to use. For example, use
http://www.wikidata.org/entity/for all wikidata entities from that namespace. This information is used by Data Foundation whenever a user navigates to a remote asset, e.g. by following a link from a Geography Taxonomy country to its Wikidata sibling. Using these namespaces, Data Foundation and the user interface can determine whether it needs to ask the database for missing triples.Remote classes can be used to inform the Search panel and similar features that it needs to query the remote data sources for instances of certain classes. In the case of the Wikidata sample Data Graph, the only remote class is Wikidata Entity, which is the superclass of all other Wikidata classes such as Wikidata Country. Whenever a user searches for Wikidata Countries, the remote endpoint will be queried to fetch matches.
Remote languages can be used to limit which literals will be loaded from the remote endpoint. This is important for cases like Wikidata where each asset has dozens of labels and descriptions, which would quickly overwhelm the user experience and slow down the system if unchecked.
To aid you with these settings, Data Foundation includes two menu items in the Modify menu of the Home asset of your remote asset collection:
Add used Remote Classes… will look for any classes that appear in
rdf:typetriples of the SPARQL endpoint and use them to populate the remote classes setting.Add used Remote Namespaces… will look for any namespaces that are used in subjects of the SPARQL endpoint and use them to populate the remote namespaces setting.
In both cases, you may want to post-process the suggested values.
Hint
If you allow editing, make sure that the Default Namespace is one of the remote namespaces, because the create asset dialogs will only allow entering URIs using the remote namespaces.
Again, use Explore > Reset Remote Storage after any change to such values.
Security Concerns for Remote Databases
If a SPARQL endpoint is protected by user name and password, an administrator needs to add the URL of the endpoint alongside with the user name and password on the Product Configuration page. This will store that user name and password in secure storage, preventing normal users from seeing those parameters.
Hint
Support for remote data sources is switched on by default. However, the system administrator can de-activate it using the disableRemoteData setup field. There is also a setup field disableRemoteEditing to generally disable remote editing.
Controlling when Remote Assets will get loaded
Note
This section is only relevant if your asset collection is not in complete mode.
Data Foundation’s user interface will recognize remote assets and load missing properties when needed. For example, the Search panel understands that it needs to query the remote database via SPARQL when you search for instances of a class that is known to exist on the remote endpoint.
For cases where the automatic loading of assets is not sufficient, Data Foundation provides control over which assets are loaded into the local storage.
There is programmatic control from the API methods loadRemoteResources and isRemoteResource from the tbs namespace.
For individual assets that may have gotten out of data, use the Reload link next to This is a Remote Asset in the header of the form, or the similar Explore > Load Remote Data….
From the Home asset, use Explore > Load All Remote Assets… as a batch process to load all instances of the configured remote classes into Data Foundation’s own database.
From the Home asset, use Explore > Load All Linked Remote Assets… to load all assets that are actually referenced by locally defined assets. For example, use this to load all Wikidata Countries that are linked from Geo Taxonomy Countries.
For programmatic access, see tbs:loadRemoteResources as one entry point.
Remote Data Matching
A frequent use case of external data sources such as Wikidata or SNOMED is as a repository of reference data where each reference data item is identified by a distinct key. For example, all Wikidata Countries have an ISO 3611-1 alpha-2 code, such as “au” for Australia. A local asset collection such as the Geography Taxonomy can use the same identifiers, making it possible to define an indirect linkage between local assets and those from remote sources.
Data Foundation’s Remote Data Matching feature makes the use of such linkage easy. Let’s look at the Geography Ontology as an example of how to set this up. When you navigate to the class Country which is a subclass of Geo concept and also Concept, follow the link to the wikidata country property shape. This property is used to link from (local) instances of Country to (remote) instances of Wikidata Country.
On the form of this property shape, scroll to the Remote Data Matching section. This section has two properties:
The local match property is the property holding the local values, here: ISO ALPHA-2 country code (
g:isoCountryCode2).The remote match property is the property at the instances of the remote class, here: ISO 3166-1 alpha-2 code (
wdt:P297).
This is typically one of the properties defined at the class that is the sh:class of the surrounding property shape, here: Wikidata Country.
The interpretation of these properties is that each time a (local) Country has a value for the local match property, the system will ask the SPARQL endpoint for matching values of the remote match property. When found, the value of the link property (here: wikidata country) will be updated automatically, making it easier for users and algorithms to navigate into the matching remote data.
Hint
The optional property local value transform may be used in scenarios where there is no exact match between local and remote values.
For example, if the local ISO codes would be in lower-case notation, you can employ a transformation function sparql:ucase to have
the local values upper-cased before they are matched to the remote values.
For programmatic access, there is a multi-function tbs:remoteMatches.
Configuration of Specific SPARQL Databases
This section provides recommendations on how to configure selected databases.
Configuring GraphDB
Ontotext GraphDB should be configured to
Ruleset: No inference - otherwise the database would return triples that are not asserted in Data Foundation, causing the local cache to contain different triples after edits.
Enable full-text search (FTS) index - needed for text search in GraphQL or the Search Panel.
Configuring Amazon Neptune
Amazon Neptune should be configured to use Full-text search (FTS) as described in the Neptune documentation. The URL of the FTS instance needs to become the value of the Neptune FTS URL property on the Remote Data tab of the home asset. Without this, auto-complete and free-text search will not work.
Configuring Ontop
Data Foundation supports the Ontop virtual graph system that allows you to wrap relational databases (in read-only mode) so that they can be queried as a SPARQL endpoint. To get started, please follow the open-source https://ontop-vkg.org/ documentation on how to define mappings from SQL tables to RDF/SHACL ontology classes and SQL columns to RDF/SHACL properties. The (commercial) products from http://ontopic.ai can help you define those mappings.
Once you have defined these mappings, use the Ontopic CLI to launch a SPARQL endpoint, then connect to that endpoint from Data Foundation. Make sure you select “Ontop” as the implementation because Ontop has slight SPARQL incompatibilities that we needed to work around in the remote data support.
Extending Wikidata
The Wikidata Sample is the recommended starting point if you want to use Wikidata within Data Foundation. It consists of:
The Wikidata Data Graph that is initially empty and incrementally populated as a local cache of the remote entities.
The Wikidata Ontology that defines the classes and properties that shall be used from the remote Wikidata server.
The file Wikidata Shapes (
http://datashapes.org/wikidata/) primarily declaring the Wikidata Entity (wikidash:Entity) base class.
You may use the Wikidata Ontology, or your own extension or variation of it, to define additional classes and properties for the domain of your interest.
Note that Wikidata is different from most other RDF data sources in that it does not use the same notion of classes and types that is known
from RDF Schema, OWL and SHACL.
Instead of using rdf:type it uses its own property wdt:P31.
Instead of using rdfs:Class and owl:Class, the Wikidata classes are themselves just ordinary wikidata entities on instance level.
The Wikidata support knows about this design pattern, and uses proxy classes from the wikidash: namespace to represent
classes of interest to the user.
The easiest procedure to get started with adding your own Wikidata classes is:
In the Wikidata Ontology, create a new subclass of Wikidata Entity. We recommend using class labels starting with Wikidata. The Wikidata Ontology uses the
wikidash:namespace and you are invited to use the same if you plan to possibly share your class definitions with TopQuadrant in the future. In this case, for example, create class Wikidata City with URIhttp://datashapes.org/wikidata/City.Use Modify > Add property shapes from Wikidata sample… to open a dialog.
In this dialog enter the Qxyz number of a suitable sample city, e.g.
Q3114for Canberra and press Load.Once it has loaded, select the most suitable Wikidata class for City, e.g. city. This will be saved as value for
wikidash:targetClassat your new class, telling Data Foundation that all instances of city shall be loaded as (RDF) instances of Wikidata City.Select the properties that you are interested in, e.g. country. These will become property shapes at the new class.
You can re-run this process later to add other properties.
Once again, note that you should go to Explore > Reset Remote Storage on the Home asset of the Wikidata Data Graph after any change to the Wikidata Ontology.
Hint
Once you are happy with your class definitions, feel free to contact TopQuadrant to have your extension added to the standard Wikidata Sample Ontology. This is also why we suggest using the same namespace for your own samples.
By the way, the Problems and Suggestions feature will try to find missing values for all properties that include wikidash:Entity among their
allowed classes.
Querying Remote Data with GraphQL
Data Foundation’s GraphQL engine is aware of graphs that are backed by a remote endpoint. It uses the declared remote classes and remote namespaces to determine if certain resources originate from a remote data source. If a request asks for instances of a remote class, the engine will try to find those instances using a SPARQL query that directly goes against the remote endpoint. For all found matches, it will then proceed caching the base info (labels and types) and, if needed for the rest of the query, also the other properties based on SHACL property shape declarations.
While this means that you do not need to make changes to your queries to work with remote data, it also may cause some queries to become significantly slower, at least for the first time until sufficient data is cached. In particular be mindful that nested queries against remote assets will each be translated into an individual SPARQL query, and those SPARQL queries may accumulate.
Attention
When you query large numbers of remote resources using GraphQL, the matching triples will all be copied into the local copy for Data Foundation. The user interface typically limits such queries to 1000 instances at most, to avoid overloading the local database. You may want to do the same in your own queries, or directly use the query services provided by the remote database.
For free-text searches and auto-complete, Data Foundation will attempt to rely on text indices provided by the database implementation where available.
If you only want to query the data from the local cache and avoid remote queries, set the optional query parameter skipRemote to true.
Querying Remote Data with SPARQL
The default SPARQL engine of Data Foundation will only operate on the triples that are available in its local database. Therefore, triples that are only stored on the remote database will not be “seen”. However, you have various ways to still query this data:
From SPARQL, use the
SERVICEkeyword.From ADS, use the function
dataset.remoteSelectto directly query the endpoint.From ADS (or SWP), use
tbs:loadRemoteResourcesprior to running SPARQL queries to force relevant data into the cache.
Validating Remote Data with SHACL
Data Foundation’s SHACL engine currently only operates on the data that is present in its local database. Uncached triples that are stored on the remote database only will not be used for validation.
To validate remote data in its own database, either use the SHACL support for the specific database or make sure that all relevant assets have been loaded into the local database, for example using Explore > Load All Remote Assets.
Needless to say, this works best if your asset collection is configured to operate in complete mode as all normal features will work as usual.
Updating Remote Data
Unless you have activated remote is editable, asset collections backed by remote data are considered read-only. Data Foundation takes control over which triples are loaded from the remote data source into its local cache but usually never modifies the remote data itself.
The suggested workflows for this set-up is that you control the updates to the remote data sources outside of Data Foundation.
For example, you may want to periodically reload your copy of SNOMED when a new version has come out.
In such cases, you should invoke the service tbs:resetRemoteStorage to make sure that all local caches are cleared.
You could follow this with calls to tbs:loadRemoteResources to repopulate the local caches if that makes sense,
i.e. if it doesn’t take too long or would overwhelm the local database.
To programmatically perform other updates, use the ADS function dataset.remoteUpdate.
If you have activated remote is editable, GraphQL mutations and ADS scripts will write through to the underlying remote database. Data Foundation will first update its internal database and then issue a SPARQL UPDATE to tell the remote endpoint about the added and deleted triples. This means that, if the remote database is unstable, in some cases the two databases may get out of synch. In those cases, you may want to reset the local database so that it reloads a fresh copy from remote.
While almost all typical operations from users will make sure that all edits to the local database will also be written into the
corresponding remote databases, there can be operations that only update the local database.
In particular, updates against the SPARQL endpoint will only affect the local database unless you operate on named graphs
that include the user name, such as urn:x-evn-master:geo:Administrator.
Attention
If the remote database has any kind of inferencing activated, the synchronization between the remote data
and the local copy that Data Foundation has may get out of sync.
For example, some databases support rdfs:subPropertyOf inferencing and if the editor asserts a value for a super-property
then the database would automatically also infer the same value for the sub-property.
However, in that case, Data Foundation’s local copy would not know about the additional triple, causing inconsistencies.
So: editing a remote database that has inferencing activated is discouraged.
Handling of Blank Nodes
The SPARQL protocol makes it very hard to work with blank nodes. This is because each query may return new blank nodes that have a distinct internal identity. As a result, it is impossible to query blank nodes across multiple queries, making incremental loading or updating very hard.
Data Foundation therefore maps all blank nodes automatically to URIs, of the form urn:blanknode:XY where XY is the internal
identifier that Data Foundation’s local Jena database uses.
This means that when you create blank nodes from Data Foundation, the nodes will remain blank nodes on the database
but are handled as URIs on the SPARQL endpoint.
Warning
If your SPARQL endpoint contains blank nodes, the behaviour of Data Foundation is non-deterministic. Please avoid using blank nodes and map them to the URN scheme above when you absolutely have to.