Importing Data with ADS
It is very common for data graphs to be populated from external files - Spreadsheets, XML, JSON etc. Users may need to upload files or files may originate from web services and are downloaded for processing. The content of these non-RDF files shall be transformed into RDF triples, typically in a given ontology. This section introduces how Active Data Shapes and SHACL can be used to facilitate such import processes.
Standard JavaScript/ECMAScript provides all commonly needed operations for complex data processing. The missing bits, on how to load data from various data sources and formats, are covered by the following subsections.
The Script Editor Panel is a good place to write importer scripts. Once you are happy with your importer scripts, you may want to turn them into Resource Actions, ADS-based Web Services or Scheduled Jobs that can be invoked repeatedly as batch operations.
Hint
The section Custom Import Script Example shows a worked out example of how to create an importer that can be launched from the Modify menu.
Working with Uploaded Files
The easiest way to get started with this technology is by trying it out, here with the Script Editor panel. This panel has a button to upload any file to the server, so that the file can be processed by a script:
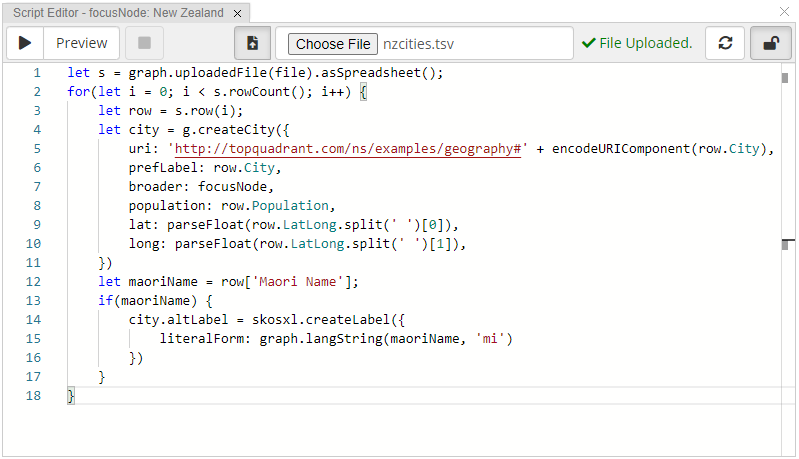
The Script Editor panel can be used to upload files and then query the content of those files
You can incrementally develop your importer script by trying it out, especially using the Preview button:
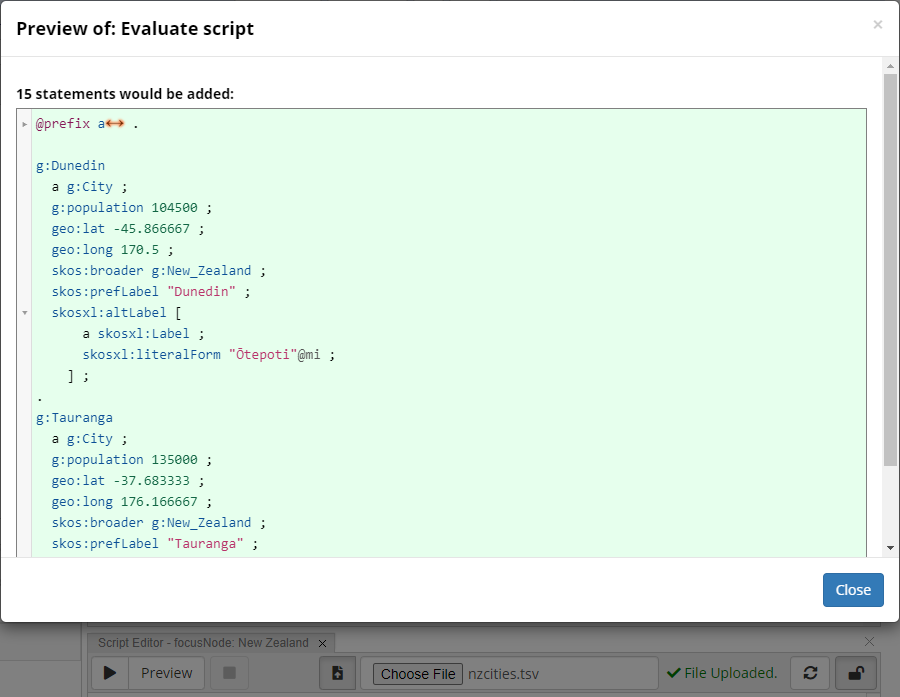
The Script Editor panel can be used to upload files and then query the content of those files
Hint
If you don’t see the Preview button, see Read-only mode versus Read/write mode.
Files that have been uploaded will go into a temporary folder on the server from which they will be removed once they are no longer needed.
They are discarded if they haven’t been accessed for more than an hour.
Scripts can access those files using a provided file identifier, which in the Script Panel from the example above is automatically called file.
The built-in function graph.uploadedFile(file) can then be used to return an instance of the JavaScript class UploadedFile which provides further functions to produce a spreadsheet object, an XML object etc.
For example, use graph.uploadedFile(file).text to get the full content from the file as a string.
Your script can then proceed with whatever it like wants to do with that file content, for example produce new instances for each row of a spreadsheet.
Downloading Files via HTTP
Files can also be downloaded through HTTP requests.
The entry point is the function IO.http()` which performs arbitrary HTTP requests and either returns the response data to the program or saves the file as an “uploaded” file so that it can be processed further.
The following example requests a tab-separated values spreadsheet from a server (here, it’s actually using a TopBraid SPARQL endpoint but that doesn’t matter). The resulting spreadsheet is saved to a temp file which can be processed further by the script, for example to count the number of rows.
1let r = IO.http({
2 url: 'http://localhost:4500/tbl/sparql',
3 method: 'POST',
4 params: {
5 query: `
6 SELECT *
7 WHERE {
8 GRAPH <http://topbraid.org/examples/kennedys> {
9 ?person a <http://topbraid.org/examples/kennedys#Person> .
10 ?person <http://topbraid.org/examples/kennedys#birthYear> ?birthYear .
11 }
12 } ORDER BY ?birthYear`
13 },
14 headers: {
15 Accept: 'text/tab-separated-values'
16 },
17 toFileSuffix: 'tsv'
18})
19IO.uploadedFile(r.file).asSpreadsheet().rows().length
As usual, you can explore the features of this API either in the Script Editor (via auto-complete etc) or on the API documentation pages.
Importing JSON
Handling JSON files from JavaScript is very easy. You simply need to fetch the text content of the uploaded file and parse it, then query the JSON like any other JavaScript object:
1let u = IO.uploadedFile(file);
2let json = JSON.parse(u.text);
3schema.createPerson({
4 uri: 'http://example.org/Person#' + encodeURIComponent(json.firstName + '_' + json.lastName),
5 givenName: json.firstName,
6 familyName: json.lastName,
7});
Importing Spreadsheets
Spreadsheet files may be uploaded as either
Tab-separated values (.tsv)
Comma-separated values (.csv)
Excel files (.xlsx)
Two distinct APIs are provided to access the rows of those files: One with a cell-based API that loads the whole spreadsheet in bulk, and an alternative streaming API for large files.
See also
In addition to these file-based importers, TopBraid 8.2 onwards includes an API to interact with spreadsheets stored online,
currently for Google Sheets and Excel files from SharePoint. This API forms the backbone of the Spreadsheet Integration.
See the inline documentation of IO.worksheets and plenty of sample code from the sheets.ttl file to get started,
and Connecting TopBraid with Google Sheets.
Bulk Loader for Spreadsheets
A unified API is provided to access the sheets, rows and columns of spreadsheets.
To get started, use .asSpreadsheet() on the UploadedFile.
This produces an object with functions to query all individual cells, the names of the columns, the rows and the sheet names.
Hint
Use auto-complete on IO.uploadedFile(file).asSpreadsheet() to see the currently available API.
By default, all cell values will be strings.
However, for Excel files the system will produce JavaScript booleans (true and false) if the cell values are recognized booleans, and numbers will be converted to JavaScript numbers automatically.
Date cells will be converted to instances of LiteralNode, i.e. you can use .lex` to retrieve the lexical form of the date in XSD format.
A small example of all this uses a tab-separated file such as:
1City Maori Name Population LatLong
2Tauranga 135000 -37.683333 176.166667
3Dunedin Ōtepoti 104500 -45.866667 170.5
An example script to convert those rows into instances of the g:City from the sample Geography Taxonomy is:
1let s = IO.uploadedFile(file).asSpreadsheet();
2for(let i = 0; i < s.rowCount(); i++) {
3 let row = s.row(i);
4 let city = g.createCity({
5 uri: 'http://topquadrant.com/ns/examples/geography#' + encodeURIComponent(row.City),
6 prefLabel: row.City,
7 broader: focusNode,
8 population: row.Population,
9 lat: parseFloat(row.LatLong.split(' ')[0]),
10 long: parseFloat(row.LatLong.split(' ')[1]),
11 })
12 let maoriName = row['Maori Name'];
13 if(maoriName) {
14 city.altLabel = skosxl.createLabel({
15 literalForm: graph.langString(maoriName, 'mi')
16 })
17 }
18}
Let’s walk through a couple of techniques used here.
The first line, let s = graph.uploadedFile(file).asSpreadsheet(); fetches an UploadedSpreadsheet instance that we can then query to walk through the columns and rows.
The for loop walks each row individually.
In each loop, the line let row = s.row(i) delivers a JavaScript object with one value for each column.
For example, if the column name is “City” then you can query the current value using row.City.
For names that are not valid JavaScript identifiers, use the array-based syntax such as row['Maori Name'].
An alternative technique (not shown here) to fetch values is through s.cell(rowIndex, colIndex).
Empty cells are not present so you would get null or undefined when you query them.
This means that in some cases you may want to insert guarding if clauses such as if(maoriName) above, or use the JavaScript ? operator to prevent null pointer exceptions.
The expression row.LatLong.split(' ') turns the combined Lat/Long string into an array of two strings, separated by spaces.
You can use any number of pre-processing steps before assigning values here - the whole power of JavaScript string processing is at your disposal.
To assign values with the correct datatype, the SHACL shape definitions help you.
In the example above, the property g.population has sh:datatype xsd:integer.
Then although the value of row.Population is a JavaScript string, the system will automatically cast it into an xsd:integer literal as part of the assignment.
In the case of lat and long however, no single sh:datatype constraint exists as the values may be either xsd:integer, xsd:decimal or xsd:double.
It is therefore necessary to use the built-in parseFloat function to produce a JavaScript number.
If you ever need to produce literals of specific datatypes, use something like graph.literal({ lex: '42', datatype: xsd.double }).
The line broader: focusNode assigns the currently selected resource (such as the g:Country of New Zealand) to the skos:broader property of the newly created city instance.
Streaming Loader for Spreadsheets
Very large spreadsheets are best imported with a streaming loader, row by row, minimizing memory consumption.
This is an alternative API that is provided for files ending with .csv and .tsv only.
Warning
The streaming loader is not available for Excel files.
The following example illustrates how to use it with a for...of loop in JavaScript.
1let s = IO.uploadedFile(file).asSpreadsheetIterator();
2for(let row of s) {
3 let city = g.createCity({
4 uri: 'http://topquadrant.com/ns/examples/geography#' + encodeURIComponent(row.City),
5 prefLabel: row.City,
6 broader: focusNode,
7 population: row.Population,
8 lat: parseFloat(row.LatLong.split(' ')[0]),
9 long: parseFloat(row.LatLong.split(' ')[1]),
10 })
11 let maoriName = row['Maori Name'];
12 if(maoriName) {
13 city.altLabel = skosxl.createLabel({
14 literalForm: graph.langString(maoriName, 'mi')
15 })
16 }
17}
The result of asSpreadsheetIterator() can also be used as a iterator directly, i.e. calling next() will return an object with the fields done and value.
Each value (row) is a JavaScript object with the column names as field names.
All cell values are strings and may need to be converted downstream in the JavaScript code.
The field s.columnNames can be used to query the names of the columns.
Importing XML
For importing XML, we provide a convenient read-only DOM-like API, based on the class XMLNode.
You can fetch an instance of XMLNode using IO.uploadedFile(file).asXML().
Hint
Use auto-complete on IO.uploadedFile(file).asXML() to see the currently available XMLNode API.
Let’s assume we have this XML file:
1<?xml version="1.0" encoding="UTF-8"?>
2<catalog>
3 <book id="bk101">
4 <author>Gambardella, Matthew</author>
5 <title>XML Developer's Guide</title>
6 <genre>Computer</genre>
7 <price>44.95</price>
8 <publish_date>2000-10-01</publish_date>
9 <description>An in-depth look at creating applications with XML.</description>
10 </book>
11 <book id="bk102">
12 <author>Ralls, Kim</author>
13 <title>Midnight Rain</title>
14 <genre>Fantasy</genre>
15 <price>5.95</price>
16 <publish_date>2000-12-16</publish_date>
17 <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description>
18 </book>
19</catalog>
Here are some example queries and their results:
1let xml = IO.uploadedFile(file).asXML();
2
3xml.nodeName; // "catalog"
4
5xml.isElement(); // true
6
7xml.childNodes.length; // 2
8
9xml.childNodes[0].id; // "bk101"
10
11xml.childNodes[1].childNodes[0].text; // "Ralls, Kim"
12
13xml.xpathNode('book[2]/@id'); // "bk102"
14
15xml.xpathNodes('book').map(node => node.id); // ["bk101","bk102"]
Importing Relational Databases via SQL
Importing data from relational databases is covered by Working with Relational Databases via SQL.