What is a Data Fabric – Q&A and Implementation Status
Data fabric is a new architecture pattern that is growing in popularity. Interest in the data fabric architecture is high as evidenced by the number of people that signed up and attended our recent webinar on “How Metadata Management Must Evolve to Support Data Fabric”.
During the webinar, we:
- Discussed the key components of a data fabric
- Described how metadata management must evolve to support data fabrics
- Run a poll to understand attendees experience with data fabrics
- Showed demos illustrating key concepts within the data fabric architecture
Poll Results
The chart below shows how webinar attendees characterized their data fabric experience.
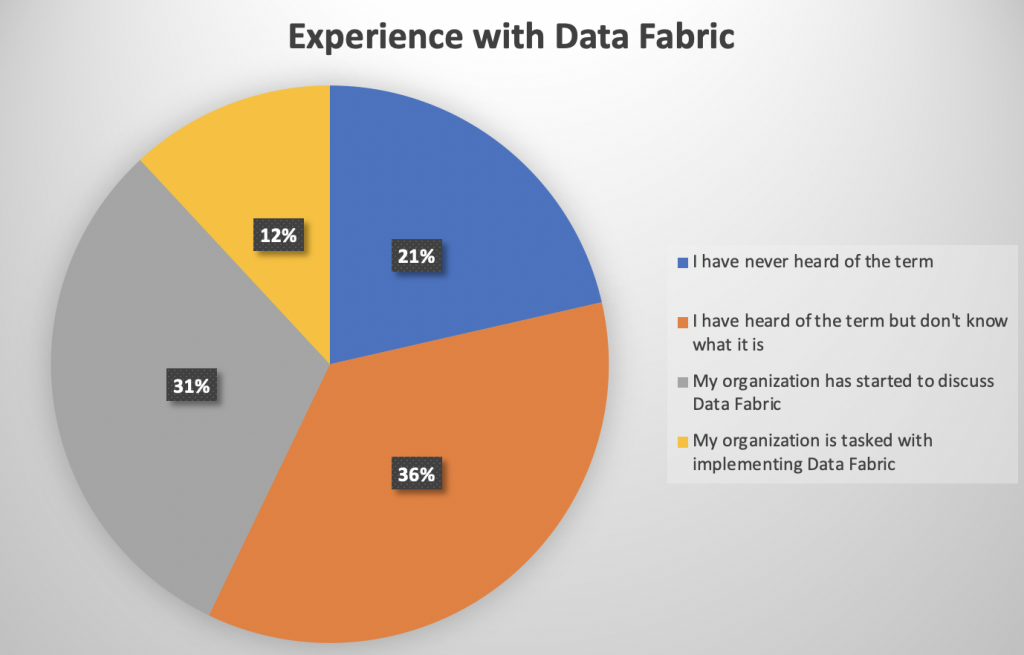
As we see, 57% did not know what a data fabric was. This includes 21% who were new to the term and 36% who have heard the term before, but did not know what it meant. The poll also shows that a growing number of organizations (31%) started to discuss data fabric implementation and, finally, 12% are in the process of implementing it.
This blog addresses questions we were asked during the webinar, but did not have time to answer. For those who did not yet watched the webinar, we start by identifying the key facts about data fabric in the section below.
What is Data Fabric?
Data fabric is an architectural pattern. Gartner, the analyst firm that coined the term data fabric, stresses that it is not a single product or even a simple collection of tools. It is a design concept that requires multiple existing and emerging data management technologies to play together in a certain way.
We have created a diagram depicting conceptual architecture for a data fabric environment.
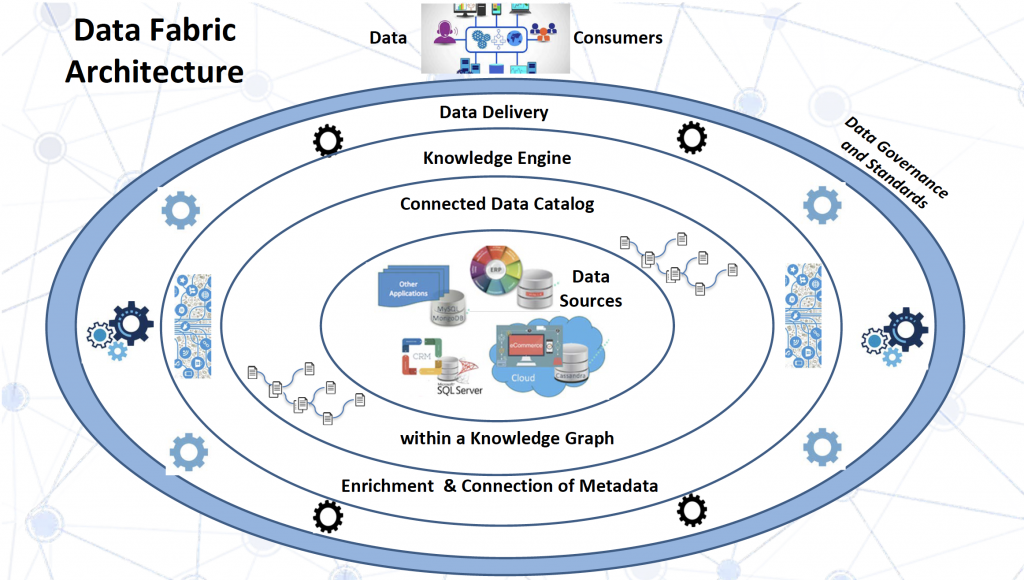
The diagram consists of five layers:
- At the center are data sources. Although shown in the middle of the diagram, in practice, they are distributed and heterogeneous.
- The fundamental concept in the data fabric architecture is cataloging distributed data sources in a knowledge graph which, to quote Gartner, reflects everything that happens to your data. This is not “your father’s data catalog”. It is a dynamic, composable and highly emergent knowledge graph – shown in the diagram as a layer surrounding the data sources.
- Metadata that lives in the knowledge graph gets collected from the data sources and from any other important source of relevant information e.g., log files. It is further interpreted, reasoned over and enriched by algorithms that take advantage of the information in the knowledge graph. Gartner calls this process activation of the metadata.
- Different data delivery tools and services plug into this architecture. They consult the knowledge graph to understand the scope and context of the available information, access rights and other important factors.
- Data governance and standards are very important to the ability of different products work together within the data fabric architecture. We have shown this aspect in an outermost, blue layer in the diagram.
Even if you do not have a subscriber access to Gartner’s research, you can see an informative overview of the data fabric concept in this free article by Gartner.
Frequently Asked Questions
We will now move on to address questions we received from the webinar participants. Generally speaking, questions fell into two categories:
1. Lifecycle of the Metadata Captured in a Knowledge Graph
This included questions and comments like:
How are verify that the metadata is correct?
Verification needs to compare the metadata in EDG with the actual data in the data asset
The depth of the capabilities for TopBraid EDG to link data at the many levels of abstractions to just about anything else is very powerful. How do you manage the inevitable complexity, especially how to enforce the “metadata quality” as the external sources change, as the organization’s needs change, and how the ontology changes?
Once the results are presented can the metadata be maintained / updated to remediate gaps in the metadata?
I see cataloguing and modeling and modeling as two different, but related things. Cataloguing is about collecting lists of data entities and data attributes, modeling is about documenting the relationships. Cataloguing can be automated, not sure modeling can be automated. Could you please comment?
Metadata gets collected from the data sources. It is correct in a sense that it reflects what actually exists. Data sources change. Thus, it is not a “one shot” collection process, but rather an ongoing process. Data sources can be re-cataloged on a regular schedule and/or on demand to ensure that the catalog contains accurate information.
TopBraid EDG offers strong support for the data stewardship processes that are indeed necessary and important. In this webinar, we have not touched on these capabilities, but they have been covered in a number of other webinars and videos such as:
Automating of Data Elements to Business Terms and
Introduction to the Change Management and Workflows
We also see cataloguing and modeling as two separate processes. Models describe data to be cataloged e.g. a model may describe that there are databases, they contain tables and views, can be hosted on some server, can be implemented using some specific technology, etc. Tables contain columns and a column may have a physical datatype, be a primary key and so on. Cataloging populates this model with the information about actual databases.
2. Connection between Data Fabric and Data Virtualization
This was represented by questions like:
Do you think the best way to implement Data Fabric is through Data Virtualization?
The outer ring of the Data Fabric Architecture picture was “Data Access”. Does EDG have a data virtualization capability to access the data?”
Can you use the metadata recorded about data sources to reach into the data source to query the data source rather than the metadata?” “You” in this context is TopBraid EDG.
How do you create this connections between data elements? Do you capture this through ER Models and Data Flows?
Data Virtualization is not the same as Data Fabric. Data Virtualization abstracts data storage across multiple locations so it is often positioned as one of the data storage patterns: https://medium.com/swlh/the-5-data-store-patterns-data-lakes-data-hubs-data-virtualization-data-federation-data-27fd75486e2c
To quote Gartner, “Data fabric should be compatible with various data delivery styles (including, but not limited to ETL, streaming, replication, messaging, and data virtualization or data microservices).” https://www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration/
It is important to stress that the architecture picture above is not an architecture of TopBraid EDG. It is a conceptual architecture for data fabric.
Data fabric is not about having a single tool. In fact, if you come across a vendor claiming that all you need to implement a data fabric is its product, you should be skeptical of the claim. If your organization is in a process of implementing this architectural approach, you should look for products that are compatible with the approach and will help you implement the necessary aspects – as opposed to products claiming to provide an “out of the box” data fabric solution.
Data fabric should be compatible with different data delivery styles, including data virtualization, but also ETL, streaming, replication, messaging and data micro services. Data delivery tools should be leveraging metadata in the knowledge graph to facilitate delivery of data. On the consuming side, there are different clients. Data fabric needs to support different types of data users and use cases. This ranges from IT users that leverage data fabric in a context of complex data integration scenarios to business users interested in self-service data preparation and access.
The role of TopBraid EDG in the data fabric architecture is to provide the knowledge graph with metadata that can be leveraged by the data delivery tools and, ultimately, data consumers. Further, EDG helps organizations consistently implement governance, security and regulatory compliance across all data.
There is support in the EDG ontologies for capturing simple as well as complex connections across data. By simple, we mean just saying that a data element is an out of something that an input to something else. By more complex, we mean capturing transformation details and other logic.
3. Ontologies and Ontology Modeling
This was represented by questions like:
Are there out of the box ontologies available in TopBraid?
How are the available ontologies aligned accurately in order to support a KG without having multiple duplicated class concepts?
Are there any techniques to speed up the ontology process other than actually linking each and every data element or asset to vocabulary list?
What is the difference between an ontology model and a data model? Is an ontology model limited to generalizations/specializations? Does it use associations?
Yes, TopBraid EDG comes packaged with pre-built ontologies. TopQuadrant built a number of ontologies to support information management initiatives. Collectively, they contain over 300 classes. See this blog for an overview of the pre-built ontologies https://www.topquadrant.com/edg-ontologies-overview/.
These ontologies “live” in a KG. KG also contains data described by the ontology models e.g., there is a class Database in the ontology and data cataloging inserts into the KG instances of databases with their properties. There are no duplicated classes to align. For example, there is a single class Database, a single class representing Database Table, Database Column, etc.
Having out of the box ontology models that describe data and information assets, systems, applications, business functions and other assets speeds up implementation. Users can extend these models and they can develop their own ontologies. Further, TopBraid EDG can auto-generate ontologies from certain data sources. For example, it can create class properties from spreadsheet columns.
Ontologies describe data, so they are data models. You can think of them as richer data models. Typically, ontologies contain classes connected by subclass relationships. Each class is defined by specifying properties of class members. These properties can be relationships (associations) and attributes.
This blog discusses ontologies as a new generation of data models: https://www.linkedin.com/pulse/how-data-modeling-different-today-irene-polikoff/.
4. Implementation and Operation
Questions in this category included:
Which triple store can we plug behind TopBraid EDG? Is it always needed with EDG?
Do you have just metadata in the graph database or do you actually have the actual data?
Which of the web services come out the box, or are they add ons?
“More data sources”: do you mean internal, external sources? When external, do you see it to be a challenge to secure long term relationships with data providers?
Where does sensitive data discovery and classification techniques fit in with your approach.
TopBraid EDG comes with a pre-built triple store, so you do not need to provide anything. If you are already using a triple store and want to populate it with data from TopBraid EDG, EDG can export RDF and it also have a SPARQL 1.1 compliant endpoint.
TopBraid EDG is populated primarily with metadata e.g., information about data elements, database tables, software that processes these data assets, stakeholders that use them, etc.
TopBraid EDG contains actual data for controlled vocabularies and reference data, e.g., reference data for countries or currencies. TopBraid EDG typically does not contain operational data, although some customers elect to, at least temporarily, ingest sample data into EDG in the course of data cataloging. Size of the samples is configurable by users.
There are many built-in services. Documentation for the web services is generated using OpenAPI Specification and is available within TopBraid EDG through an interactive Swagger UI (https://swagger.io/specification/).
TopBraid EDG also supports GraphQL and SPARQL Access. For documentation of the GraphQL support in EDG, see https://www.topquadrant.com/doc/7.2/graphql/index.html.
TopBraid EDG works with both, internal and external sources.
TopBraid EDG predefined a number of properties to describe sensitive information. For example:

