How TopQuadrant is embracing Large Language Models (LLMs)
By Steve Hedden
The rise of generative AI, specifically large language models (LLM) like ChatGPT, have encouraged almost every enterprise to try to unlock or ‘chat’ with their data. The goal is often similar: to provide employees or customers with some sort of ‘digital assistant’ to get them the right information faster. There are many problems with these solutions: they are unexplainable ‘black box’ models, they often struggle with factual domain-specific knowledge, and they can ‘hallucinate’ i.e. return false information. For highly regulated industries that prioritize precision, accuracy, and compliance, these problems are unacceptable.
At TopQuadrant, we firmly believe a good AI strategy starts with a good data strategy. The potential for AI to turn vast swamps of enterprise data into actionable insights is appealing, but it is often far more difficult and dangerous than we think due to data issues. By some estimates, over 80 percent of AI projects fail, often because of poor data infrastructure.1 Gartner predicts that, “Through 2025, at least 30 percent of GenAI projects will be abandoned after proof of concept (POC) due to poor data quality, inadequate risk controls, escalating costs or unclear business value.”2
Knowledge graphs are also implemented with the aim of ‘unlocking’ data. A knowledge graph is a way to organize, connect, and govern data, making it easier to understand and use. The potential complementarity is clear: many of the weaknesses of LLMs, that they are black-box models and struggle with factual knowledge, are some of the KGs’ greatest strengths. KGs are, essentially, collections of facts, and they are fully interpretable.3 4 This post will describe the different ways we are working with our Fortune 500 customer base to implement KGs and LLMs together. We’re excited to share these new capabilities and look forward to seeing how they can drive innovation and impact across your organization.
How can KGs and LLMs be implemented together?
We believe in using AI as much as possible to build, maintain, and extend knowledge graphs, and also that KGs are necessary for enterprises looking to adopt AI technologies. Below is a diagram showing our vision for how TopBraid EDG can facilitate both the construction of KGs leveraging LLM-tech, and the implementation of more accurate and secure AI applications. While this is a vision of where we are going, we have already released early versions of many of these capabilities.
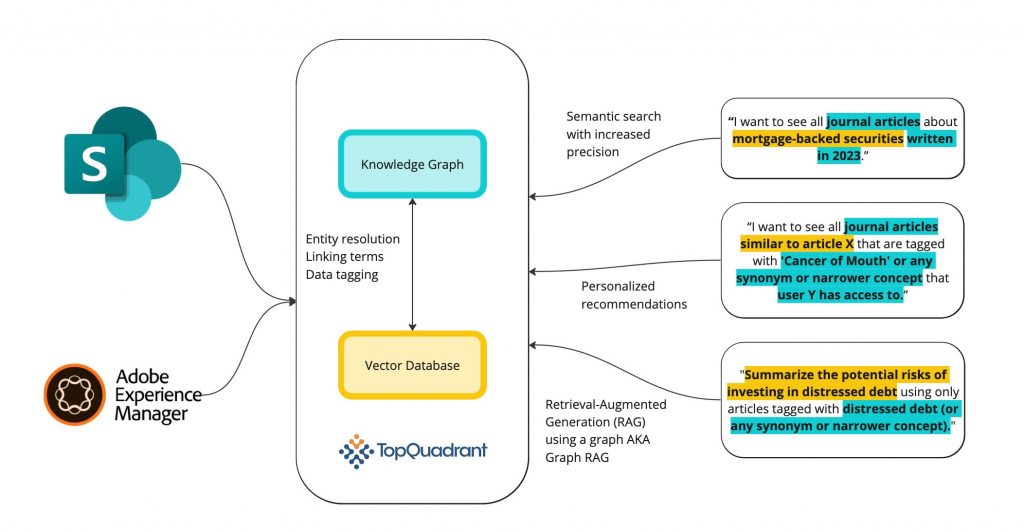
On the left side you can see how TopBraid EDG is integrated with both Adobe Experience Manager (AEM) and SharePoint. The rise of generative AI has highlighted the critical role knowledge graphs play in governing and improving the relevance of AI-driven applications, while also revealing areas for growth. Specifically, LLMs have highlighted the need to better integrate unstructured data into knowledge graphs. We’re addressing these needs by focusing on unstructured data and integrations with content management systems (CMS) like Adobe Experience Manager (AEM) and SharePoint.
A key part of this vision is the integration of a vector database and a vectorization service model in the EDG infrastructure. We now offer a vector database (specifically Weaviate) as an optional part of the TopBraid infrastructure. The vector database, paired with access to a vectorization service, allows EDG users to vectorize their ontologies and controlled vocabularies to facilitate many use cases and applications. We provide a vectorization service hosted on our own TopQuadrant servers, but users can also configure their vector database to point at any other vectorization service URL if desired.5 This vectorized knowledge graph enables users to use LLM-tech to build, maintain, and extend their KGs. Some examples of ways you can do this are listed in the diagram: entity resolution, linking terms, and data tagging.
On the right side of the diagram, you can see the different ways that KGs and vector databases can be used together for safer and more accurate AI applications. A vectorized knowledge graph can also be used for semantic search, personalized recommendations, and graph RAG. In EDG, users can query both the vector database and the knowledge graph with the same SPARQL query, enabling advanced semantic searches and laying the groundwork for recommendations, and RAG applications. In the diagram, you can see how some parts of the prompt are sent to the vector database to return other similar nodes, while other parts of the query can be used with the knowledge graph to filter the results. For example, I can query the vector database for all articles similar to the natural language term, ‘mortgage-backed securities,’ and the knowledge graph to filter the returned articles by date and type.
What is a vector database?
A vector database is simply a database that stores vectors, or lists of numbers. That wouldn’t be very interesting, except that it is possible to encode an incredible amount of information in a long list of numbers. Models like OpenAI’s GPT series, Meta’s LLaMA series, and Google’s Geminis were trained on large amounts of data, mostly unstructured. They are able to convert everything they ‘learned’ from their vast amounts of training data into the vector representation of a word or phrase. For example, the meanings for ‘dog’ and ‘canine’ are similar, even though the strings themselves are different. A good vectorization model would generate vector representations of ‘dog’ and ‘canine’ that are very similar. The process of turning text into vectors is called vectorization (or sometimes embedding) and is one of the key technological components driving large language models like GPT.
For more information: https://weaviate.io/blog/vector-embeddings-explained
Once a dataset is vectorized, it becomes incredibly easy to perform both semantic search and similarity searches. For example, if I search for ‘puppy’ in my vector database, it will vectorize the word ‘puppy’ and return other entities ‘close’ to that vector, which are likely to be words like ‘dog’ and ‘canine’. Similarly, if I know the ID for the term ‘puppy’, I can return all similar entities, which, again, is likely to be terms like ‘dog’ and ‘canine’. These calculations can be done very quickly and can take advantage of the vast quantities of data the models have been trained on. This technology can be used to improve capabilities for building, maintaining, and extending knowledge graphs as well as more performant and secure AI applications.
How can LLMs improve capabilities for building knowledge graphs?
The central part of the diagram above listed several ways vector databases can be used to build knowledge graphs. We have made progress on several of these capabilities – details below.
- Entity resolution and alignment. The first version of this capability is something we refer to at TopQuadrant as ‘crosswalking’. It involves mapping two taxonomies to each other. If one taxonomy (the target) is vectorized, you can align it with another taxonomy (the source) by treating each entity in the source taxonomy as a search query in your vector database. The closest matches are then used to create the mapping.6
- Tagging unstructured data (aka AutoClassification). If you have a taxonomy you want to use for tagging content, you begin by vectorizing your taxonomy. Next, you can vectorize a document or a section of a document and identify the nearest terms from the vectorized taxonomy. In this way, your content will be automatically tagged with terms from your taxonomy based on the meaning of the words in the document.7
- Additional enrichment: We are currently investigating additional ways LLMs and vector databases can be used to enrich knowledge graphs. Some examples are: entity extraction to populate a taxonomy/ontology, class and relationship extraction, natural language search, summarization of search results, class definition generation, and others. Reach out if you want to learn more or partner with us on any of these topics.
How can KGs make more accurate and secure AI applications?
An LLM alone will not make all data FAIR (Findable, Accessible, Interoperable, and Reusable). Just as data lakes did not solve data integration problems, neither will vector databases or LLMs. If your data is poorly structured, storing it in one place isn’t going to help. That is how the promise of data lakes became the scourge of data swamps. Likewise, if your data is poorly structured, vectorizing it isn’t going to solve your problems, it’s just going to create a new headache: a vectorized data swamp. Recent research reveals that LLMs exhibit subpar performance (16 percent accuracy) when querying structured data, yet this accuracy triples when employed alongside a KG.8 Here are some of the ways KGs can improve the security and accuracy of LLM-based applications.
- Data governance, access control, and regulatory compliance: Most large enterprises do not want one AI application that is trained on all of the enterprise’s data and we don’t recommend that. You wouldn’t want internal payroll data falling into a customer facing chatbot. Data governance is a crucial component to a successful AI roadmap. TopQuadrant has been a leader in enterprise data governance for decades, and the rise of generative AI has only reinforced the necessity of this expertise.
- Accuracy and contextual understanding (often via Graph RAG): Retrieval-Augmented Generation (RAG) is when a prompt meant for a large language model (LLM) is augmented with additional contextual information. When the knowledge base supplying that additional information is a graph, it is often called Graph RAG. We are working towards Graph RAG solutions at TopQuadrant in several ways:
- Vectorized knowledge graphs: can be used for graph RAG applications. For example, a natural language prompt, like the phrase “dog walking”, can be sent to the vector database which would return all documents most similar to this phrase in the vector space. Since each of those entities is also an entity in the knowledge graph, we can use advanced filtering and inferencing to refine the search results. This can result in more accurate results and can also be used as a governance layer – suppose the person who sent the prompt only has access to certain dog walking documents. TopBraid EDG already has a SPARQL API that allows users to query the knowledge graph, but we have now enabled queries of the vectorized knowledge graph within the SPARQL query. This means you can include natural language queries within the SPARQL query.
- Content Management System (CMS) integrations: The rise of LLMs has brought new attention to the need to incorporate unstructured data into knowledge graphs. For this reason, we are also building out integrations with content management systems like SharePoint and Adobe Experience Manager (AEM). Many of our customers store and manage their content in one of these CMSs. Rather than duplicate all of your content in a knowledge graph, you can use TopBraid EDG to store metadata and references to the underlying content which can then be retrieved at query time. Additionally, you can use the EDG-CMS integration to ensure that the terms used to tag documents in the CMS align with the controlled vocabularies managed in EDG.
- True Graph RAG: we are building out additional capabilities to enable Graph RAG such as: document chunking, more advanced querying algorithms, and integrating with LLMs for an end-to-end solution. These capabilities will be available in future EDG releases.
- Efficiency and scalability: Creating multiple, disconnected applications leads to inefficiencies, often described as a “software wasteland,” a term coined by Dave McComb. Even if these applications are AI-driven, their isolated nature results in duplicated data and code, creating unnecessary redundancies. Knowledge Graphs (KGs) offer a solution by enabling seamless data integration across the enterprise, reducing these redundancies and improving overall efficiency.
What does the future of KGs and LLMs look like?
This is a rapidly changing area and there are new innovations everyday. However, we strongly believe knowledge graphs will play a central part in helping our customers achieve their AI ambitions. Knowledge graphs are going to be a key part of managing data and injecting business context into AI solutions. We at TopQuadrant will be actively investing in ways of leveraging AI to make it easier for taxonomists to build KGs and to ensure that the KGs they build can be consumed by chatbots, digital assistants, or any other AI application. We are actively seeking partnerships with others interested in this fascinating frontier–please reach out to us to talk about how we can work together.
- https://www.rand.org/pubs/research_reports/RRA2680-1.html ↩︎
- https://www.gartner.com/en/newsroom/press-releases/2024-07-29-gartner-predicts-30-percent-of-generative-ai-projects-will-be-abandoned-after-proof-of-concept-by-end-of-2025 ↩︎
- Unifying Large Language Models and Knowledge Graphs: A Roadmap, Shirui Pan et al. 2023. <https://arxiv.org/abs/2306.08302> ↩︎
- Adopt a Data Semantics Approach to Drive Business Value,” Gartner Report by Guido De Simoni, Robert Thanaraj, Henry Cook, July 28, 2023 ↩︎
- Documentation: https://archive.topquadrant.com/doc/8.1/reference/TopBraidAIServiceSection.html ↩︎
- Documentation: https://www.topquadrant.com/doc/8.1/user_guide/vector_index/index.html?#use-the-vector-index-for-crosswalks ↩︎
- https://www.topquadrant.com/doc/8.1/user_guide/vector_index/index.html?#using-the-vector-index-in-a-content-tag-set ↩︎
- A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases, Juan Sequeda and Dean Allemang and Bryon Jacob, 2023. <https://arxiv.org/abs/2311.07509> ↩︎






