Deriving Foreign Keys with TopBraid EDG
In this blog, we will explore approaches for post-processing a data source information to derive the foreign key relationships that are not readily available in a database schema.
Some organizations may not use FOREIGN keys in their SQL databases due to performance limitations and/or the fact that they may have databases which prevent effective use of the foreign key constraints. If this information is not captured in a database schema (i.e., system tables), TopBraid EDG will not be able to get it during the cataloging of a data source. Yet, it is often possible to post-process data source information to identify foreign keys with a high degree of certainty. Let’s discuss how.
Capturing Foreign Key Information in EDG
First, let’s take a look at how foreign keys are stored in EDG. The diagram below shows a Foreign Key class.
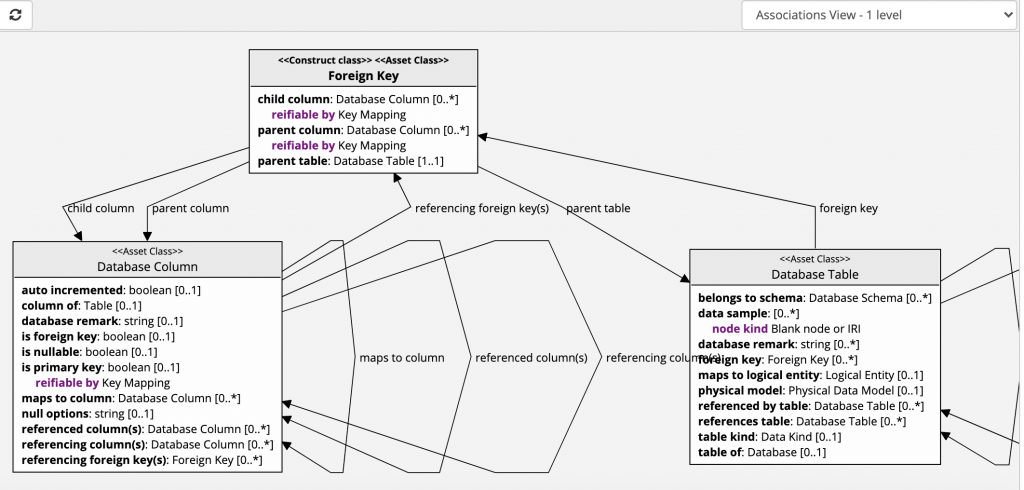
As you can see from the diagram, instances of a Foreign Key class are connected to a column that is a foreign key using the “child column” relationship. Its QName is edg:childColumn. If a column is a foreign key, the value of its edg:isForeignKey property should be true. Similarly, a Foreign Key resource is connected to a primary key column using the “parent column” relationship. Its QName is edg:parentColumn. If a column is a primary key, the value of its edg:isPrimaryKey property should be true.
For example, the following snippet in Turtle captures the fact that a CUSTOMERID column in the ORDERS table of NORTHWIND database is a foreign key corresponding to the CUSTOMERID column in the CUSTOMERS table.
<urn:x-evn-master:northwind/ORDERSCUSTOMER>
a edg:ForeignKey ;
edg:childColumn <urn:x-evn-master:northwind/COL_NORTHWIND.DBO%2EORDERS.CUSTOMERID> ;
edg:parentColumn <urn:x-evn-master:northwind/COL_NORTHWIND.DBO%2ECUSTOMERS.CUSTOMERID> ;
rdfs:label “ORDERS_CUSTOMER” ;
.
While the diagram shows the “foreign key” relationship from a Database Table to a Foreign Key, it does not need to be stored. It can be derived by following the inverse of the “child column”/”column of” path.
You may note that the “child column”, “parent column” and “is primary key” properties are reifiable by the Key Mapping. This is used only for composite keys. Key Mapping has a single property – “key order”, defined as follows:
edg:KeyMapping-keyOrder
a sh:PropertyShape ;
sh:path edg:keyOrder ;
rdfs:isDefinedBy <http://edg.topbraid.solutions/1.0/schema/datamodels> ;
sh:datatype xsd:integer ;
sh:maxCount 1;
sh:description “The order expresses the position of the column in the key.” ;
sh:name “key order” ;
sh:order “10”^^xsd:decimal ;
.
If a primary key (and corresponding foreign keys) is composed of multiple columns, then for each participating column there will be edg:keyOrder annotation to specify the order of a column in a key. This is accomplished using RDF* style reification. For more information, see this page in the User Guide.
Now that we have described how to store foreign key information, let’s discuss how to identify foreign keys.
Using Column Names to Identify Foreign Keys
Often, foreign keys can be identified by examining column names. For example, as described above, CUSTOMERS table may have CUSTOMERID column as its primary key. ORDERS table may also have CUSTOMERID table and we know that it is not a primary key. In this situation, we can make a guess that the CUSOMERID column in the ORDERS table is actually a foreign key.
A query shown below looks for all columns that are primary keys and identifies columns in a different table that have exactly the same name and are not marked as a primary key. The query only looks for non-composite primary keys i.e., only one column is used to specify the primary key. This is accomplished using the first FILTER NOT EXISTS clause of the query.
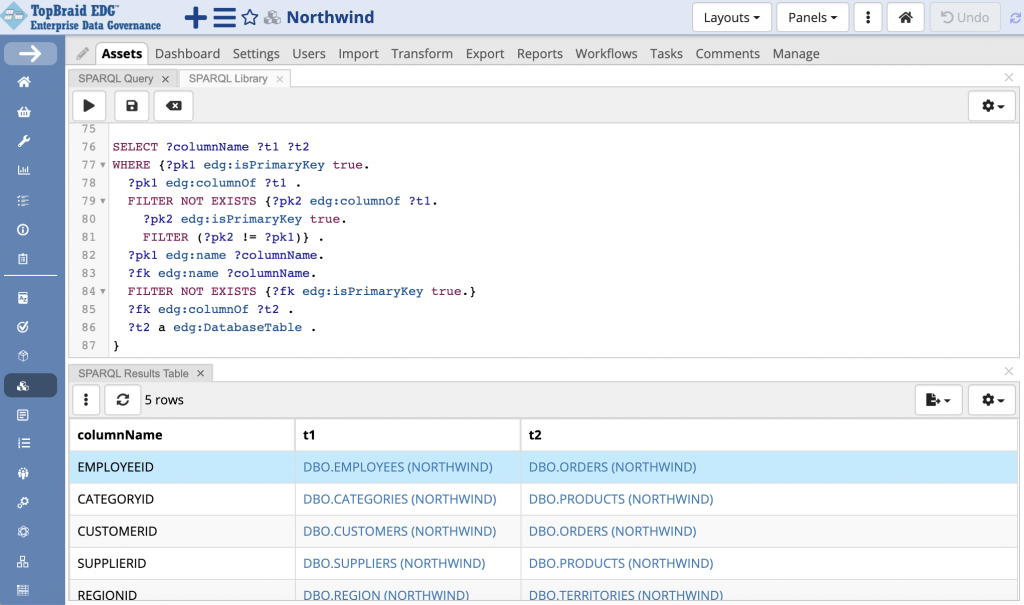
Running this query on Northwind, identifies three tables that are likely to have foreign keys: ORDERS, PRODUCTS and TERRITORIES. For two of these tables we have identified two foreign keys. For ORDERS this is EMPLOYEEID as a foreign key to EMPLOYEES table and CUSTOMERID as a foreign key to the CUSTOMERS table. For PRODUCTS this is SUPPLIERID as a foreign key to the SUPPLIERS table and CATEGORYID as a foreign key to the CATEGORIES table.
We can now run a query to create instances of the Foreign Key class. To address the compound primary key situation we can define a slightly different query, but the idea is the same.
We could also further increase probability that our foreign key guesses are correct by using information gathered in data profiling. One of the statistics captured by EDG for each column is a number of unique data values. The number of unique data values in a foreign key column should be less or equal to the number of the unique data values in a primary key column. We could also look at the physical datatypes of each column to ensure that they are compatible.
Using Data to Identify Foreign Keys
What if your column names are inconsistent? For example, CUSTOMERS tables may use CUSTOMERID column, but ORDERS table may use CUSTID as a column that stores IDs of customers who placed orders.
In such cases, the query shown above would not work as it relies on the consistent naming of columns. If your database does not use consistent column names, you may try using Problems and Suggestions algorithm that recommends mapping of data elements to glossary terms.
This algorithm relies on the data value rules that are specified for glossary terms. These rules are SHACL shapes that describe a shape of values matching a term. For example, a customer ID may follow a certain pattern e.g., be 11 characters long, have either AB or CD as the first two character, a dash as the third and have numbers in the 4th through 11th characters. With this, you can create a Customer Identifier glossary term in a Glossary and define such data value rule for it. If you include this Glossary in a Data Asset collection, Problems and Suggestions will look through the data samples and data statistics captured in a Data Asset collection and will identify data elements known to contain data matching a specified shape. If one of the data elements is known to be a primary key of a table, then other suggested data elements could be foreign keys provided they belong to different tables.
Yet another options is to use a glossary term to store commonly used alternative column names and abbreviations for the Customer Identifier term such as CUSTOMERID, CUSTID, C_ID and so on. You can build the list of names over time as you add more cataloged data sources.
When to Run Post-Processing to Derive Foreign Keys
When you first catalog a new data source, you will probably do it using EDG UI by clicking on the Import Tab and then selecting Import Using JDBC.
Once import completes, you can try the alternatives described here to see which one gives you the best result. This will depend on your specific database and the naming conventions it uses.
After your initial ingest, you will probably be running data cataloging on schedule to capture any changes in the cataloged sources. If so, you will be using workflows to store and review changes. In this case, it would make sense to define a workflow that would run the appropriate foreign key identification logic right after the cataloging and data profiling/data sampling.






