Accessing the SPARQL endpoint
In the following sections we look specifically at how to access the SPARQL endpoint with calls from external systems. First we look at accessing the endpoint via EDGs Swagger API and cURL . Next, how to access via the SPARQL client. And finally how to call the endpoint with some sample Python code (this will require a basic understanding of `Python`_).
To learn about SPARQL in EDG, please consult the SPARQL documentation.
Contents
1. Accessing SPARQL via Swagger and cURL
In this section you will learn to navigate to Swaggers SPARQL endpoint, and execute a simple SPARQL query. We will be querying over EDG’s sample data.
To learn more about accessing and using Swagger in EDG, please consult the following documentation: Web services and Swagger and Swagger References.
The first step is to access the reports tab in your target asset collection, i.e. the asset collection which you wish to run your SPARQL query. We are going to query the “Kennedy Family” Data Graph. So, after selecting this data graph, go to the reports tab and select “Web Services Swagger UI”, and navigate to “SPARQL”.

The SPARQL Swagger endpoint in the reports tab for the Kennedy Family asset collection
Under SPARQL you will see two options, either access SPARQL endpoint using GET or POST requests. Let us test POST. Click on it and selecting “Try it out”
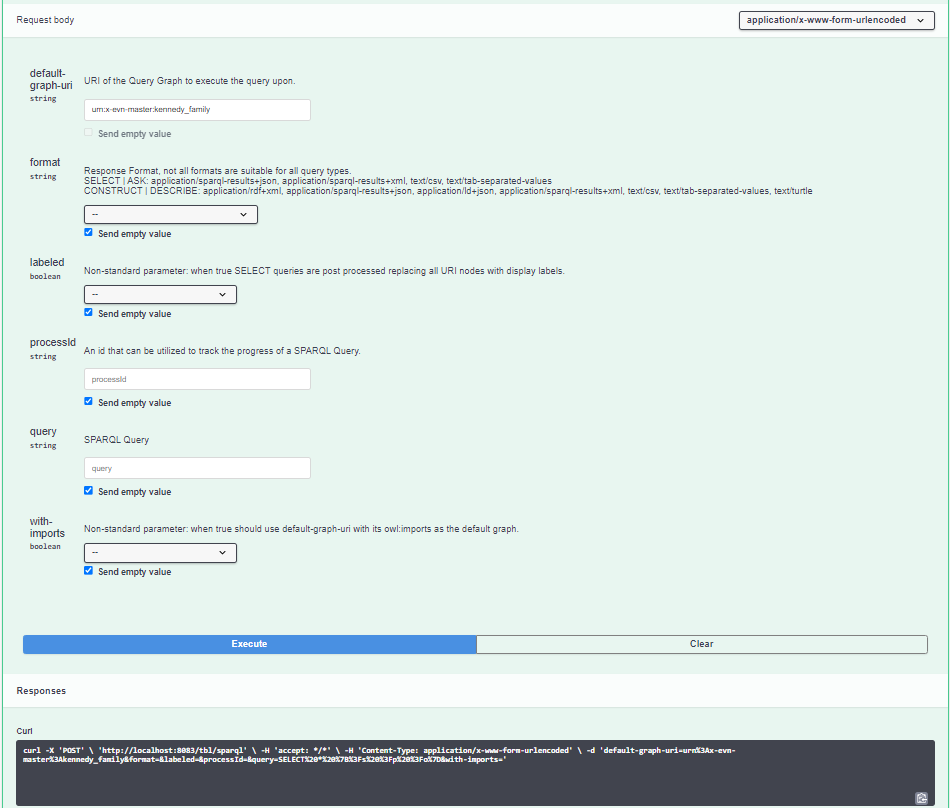
The SPARQL endpoint in Swagger for the Kennedy Family asset collection
The default-graph-uri will already have the asset collections URI as a value, but it is possible to query over other asset collections by editing this field. As you have selected the Kennedy Family data graph, this value should read “urn:x-evn-master:kennedy_family”. There are several other options available here, for example, you can specify the format of the response (formats are dependant on the type of query), whether to include imported graphs, etc. These can be viewed in Swagger as optional fields. We are only interested here in the query field.
Enter the following SPARQL query into the query field:
PREFIX schema: <http://schema.org/>
SELECT *
{
?s a schema:Person;
schema:birthDate ?birthDate;
schema:deathDate ?deathDate;
schema:gender ?gender.
}
The response body is a downloadable file, so you can click the “Download file” option to download the result of this query.
The same query can be executed using the following cURL command (this has been adapted slightly from what Swagger provides):
curl -X POST \
'http://localhost:8083/tbl/sparql' \
-H 'accept: */*' \
-H 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'default-graph-uri=urn:x-evn-master:kennedy_family' \
--data-urlencode 'format=' \
--data-urlencode 'labeled=' \
--data-urlencode 'processId=' \
--data-urlencode 'query=PREFIX schema: <http://schema.org/> SELECT * { ?s a schema:Person; schema:birthDate ?birthDate; schema:deathDate ?deathDate; schema:gender ?gender.}' \
--data-urlencode 'with-imports='
The SPARQL endpoint has a URL of http://localhost:8083/tbl/sparql. This example assumes you are running on localhost with no authentication. When running EDG on SaaS you would replace “localhost:8083” with the URL of your server. For more on the differents methods for authenticating, please see the documentation on authentication, or consult the previous section on authentication for accessing the GraphQL endpoint GraphQL endpoint authentication
2. Accessing SPARQL endpoint client
You can also access a SPARQL client by putting http://localhost:8083/tbl/sparql into your browser. This gives you access to the EDG SPARQL endpoint client. Here you can select a default graph from the drop down menu, and run queries against that graph. You can also see the URIs for each of the different graphs which are available to query against, including the change graphs.
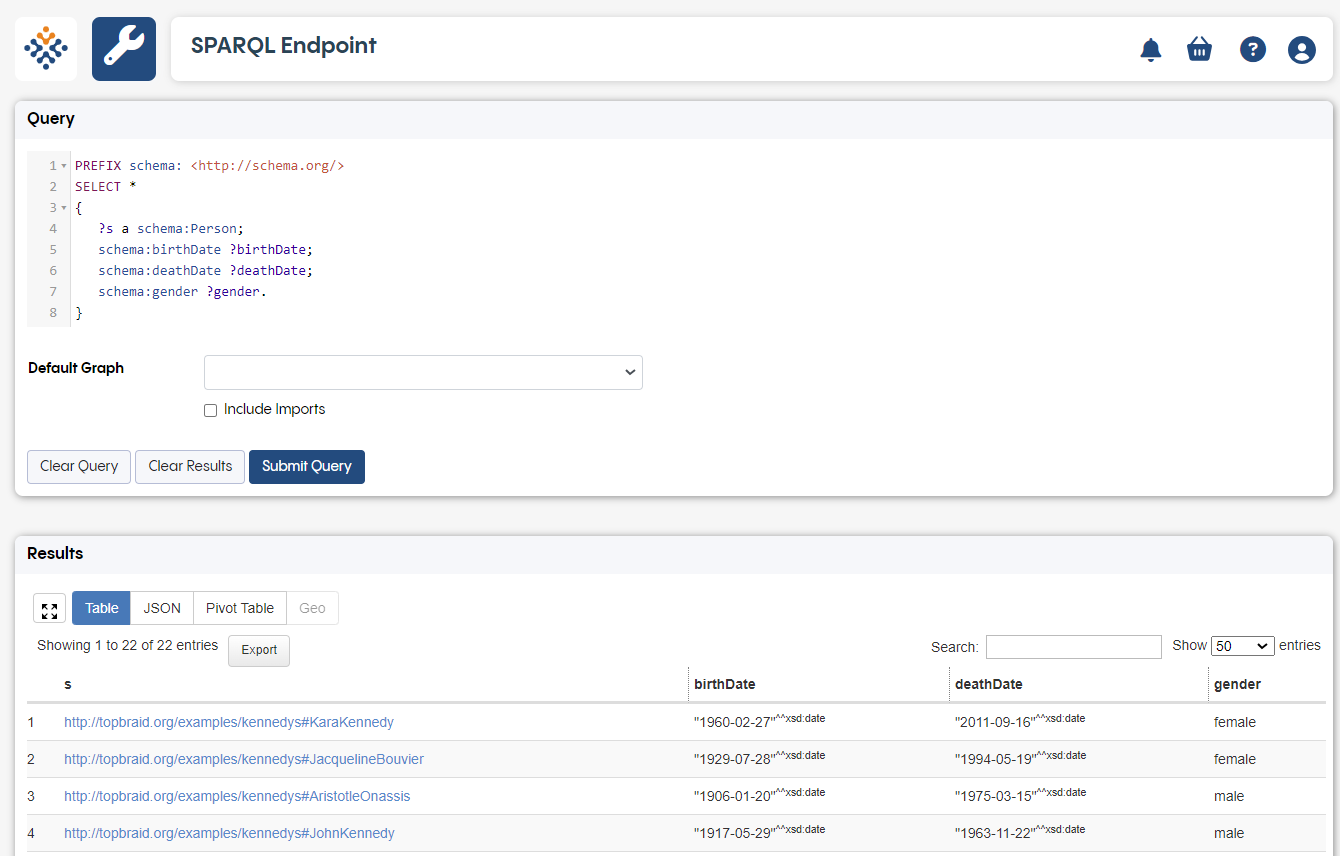
The SPARQL endpoint client querying the Kennedy Family asset collection
3. Accessing SPARQL using a Python Script
In this section we take the above SPARQL endpoint and write a piece of Python script to allow you to make a call to EDG, which takes as parameters the URL of your server, the asset collection, and the query. The python code will need to import two libraries, requests (to handle the HTTP requests) and sys (to handle input parameters). Next we write a main function, which first checks we have provided the correct number of parameters, and if yes, takes these parameters, stores them as variables, and passes them to the function “sparql_query”.
import argparse
import requests
def main():
parser = argparse.ArgumentParser(description="Sparql Query")
parser.add_argument("--input_url", required=True, help="Input URL")
parser.add_argument("--default_graph_uri", required=True, help="Default Graph URI")
parser.add_argument("--query", required=True, help="SPARQL Query")
args = parser.parse_args()
sparql_query(args.input_url, args.default_graph_uri, args.query)
Next we write the sparql_query function. This function takes the input url, the name of the asset collection, and finally the SPARQL query and uses these to generate a HTTP post request. If successful, it returns the response and prints to console, and if not it generates an error message.
def sparql_query(input_url, default_graph_uri, query):
url = f"{input_url}/tbl/sparql"
headers = {"accept": "*/*", "Content-Type": "application/x-www-form-urlencoded"}
payload = {
"default-graph-uri": default_graph_uri,
"format": "application/sparql-results+json",
"labeled": "",
"processId": "",
"query": query,
"with-imports": "",
}
response = requests.post(url, headers=headers, data=payload)
if response.status_code == 200:
return response.text
else:
error_message = (
f"Request failed with status code {response.status_code}: {response.text}"
)
raise Exception(error_message)
if __name__ == "__main__":
main()
You can download the complete code example here sparql_query.py
To test this, running EDG Studio locally, use the following command -
python sparql_query.py --input_url "http://localhost:8083" --default_graph_uri "urn:x-evn-master:kennedy_family" --query "PREFIX schema: <http://schema.org/> SELECT * { ?s a schema:Person; schema:birthDate ?birthDate; schema:deathDate ?deathDate; schema:gender ?gender.}"